Been a while since I have worked on this project. Time to get back at it. Though I do have to admit a certain loss of interest. That said, I believe it is best that I complete it.
Random State
A wee aside.
I had been looking into saving random generator state following training. Then using the saved state to restart the generator where it left off. Couldn’t really figure out an easy way to do so. But I do want to provide for reproducibility. So I modified the code that is used to set the torch random seed.
# modify so that get a specific seed for resumed training
# cfg.start_ep defaults to 0 if not resuming training,
# otherwise it is expected to be specified as a parameter
# when running the module from command line
if trn_model:
torch.manual_seed(42 + cfg.start_ep)
Full Training Loop
This is a little out of order, but I added:
- the code to save checkpoint at the end of the training loop.
- the code to load the last checkpoint if resuming training
- the code to instantiate the logger
- the code to save training run losses to file and display
This is the initial refactor using the training run test code. Once I add the full training loop there will be some additional code for the logger. And perhaps for running simple tests every epoch. Not sure about the latter.
... ...
if trn_model:
# set up logger for losses
loss_nms = ["lstm"]
lgr_loss = Logger(cfg.run_nm, cfg.sv_chk_cyc, loss_nms)
# set up cost function, optimizer, etc.
optr = optim.Adam(lstm.parameters(), lr=lr)
f_loss = nn.CrossEntropyLoss()
if cfg.resume:
print(f"\nresuming training at epoch {cfg.start_ep}, loading saved states")
utl.ld_chkpt(cfg.sv_dir/f"lstm_{cfg.start_ep - 1}.pt", lstm, optr)
if tst_model:
d_tst = 5000
cfg.epochs = 1
else:
d_tst = False
fini_ep = cfg.start_ep + cfg.epochs
print(f"running epochs in range({cfg.start_ep}, {fini_ep})")
if tst_model:
print(f"\tearly end after {d_tst} iterations")
st_tm = time.perf_counter()
for ep in range(cfg.start_ep, fini_ep):
e_losses = do_epoch(0, lstm, tk_ldr, optr, f_loss, cfg.batch_sz, 5, d_tst=d_tst, verbose=tst_model)
all_losses = {"lstm": e_losses}
lgr_loss.log_losses(all_losses)
nd_tm = time.perf_counter()
if tst_model:
print(e_losses)
print(f"time to process {d_tst} interations: {nd_tm - st_tm}")
if d_tst:
iteration = d_tst
else:
iteration = fini_ep * len(tk_ldr)
utl.sv_chkpt(cfg.run_nm, fini_ep, lstm, optr, lr_schd=None,
batch_sz=cfg.batch_sz, fl_pth=cfg.sv_dir/f"lstm_{fini_ep}.pt")
# save losses to file and show plot
lgr_loss.to_file(cfg.sv_dir, fini_ep, iteration)
lgr_loss.plot_losses()
With tst_model set to True I got the following output in the terminal.
(mclp-3.12) PS F:\learn\mcl_pytorch\proj8> python nlp.py -rn rk1 -bs 32
{'run_nm': 'rk1', 'batch_sz': 32, 'dataset_nm': 'no_nm', 'sv_img_cyc': 150, 'sv_chk_cyc': 50, 'resume': False, 'start_ep': 0, 'epochs': 5, 'num_res_blks': 9, 'x_disc': 1, 'x_genr': 1, 'x_eps': 0, 'use_lrs': False, 'lrs_unit': 'batch', 'lrs_eps': 5, 'lrs_init': 0.01, 'lrs_steps': 25, 'lrs_wmup': 0}
image and checkpoint directories created: runs\rk1_img & runs\rk1_sv
took 3.4048644001595676 to generate pairs
running epochs in range(0, 1)
early end after 5000 iterations
epoch: 1, iteration: 500 -> loss: 6.235019683837891
epoch: 1, iteration: 1000 -> loss: 6.2984843254089355
epoch: 1, iteration: 1500 -> loss: 6.271887302398682
epoch: 1, iteration: 2000 -> loss: 6.191472053527832
epoch: 1, iteration: 2500 -> loss: 6.005038261413574
epoch: 1, iteration: 3000 -> loss: 6.034036636352539
epoch: 1, iteration: 3500 -> loss: 5.877449989318848
epoch: 1, iteration: 4000 -> loss: 5.846343517303467
epoch: 1, iteration: 4500 -> loss: 5.715307712554932
epoch: 1, iteration: 5000 -> loss: 5.6238603591918945
[6.235019683837891, 6.2984843254089355, 6.271887302398682, 6.191472053527832, 6.005038261413574, 6.034036636352539, 5.877449989318848, 5.846343517303467, 5.715307712554932, 5.6238603591918945]
time to process 5000 interations: 188.1657611001283
And, here’s a look at the GPU state after 2,500 iterations. It pretty much stayed there for the remaining 2,500 iterations.
PS F:\learn\mcl_pytorch> nvidia-smi
Sun Mar 2 15:43:08 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 566.14 Driver Version: 566.14 CUDA Version: 12.7 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA WDDM | 00000000:49:00.0 Off | N/A |
| 61% 64C P2 179W / 260W | 1045MiB / 11264MiB | 84% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
And here’s the plot of the losses generated in the test.
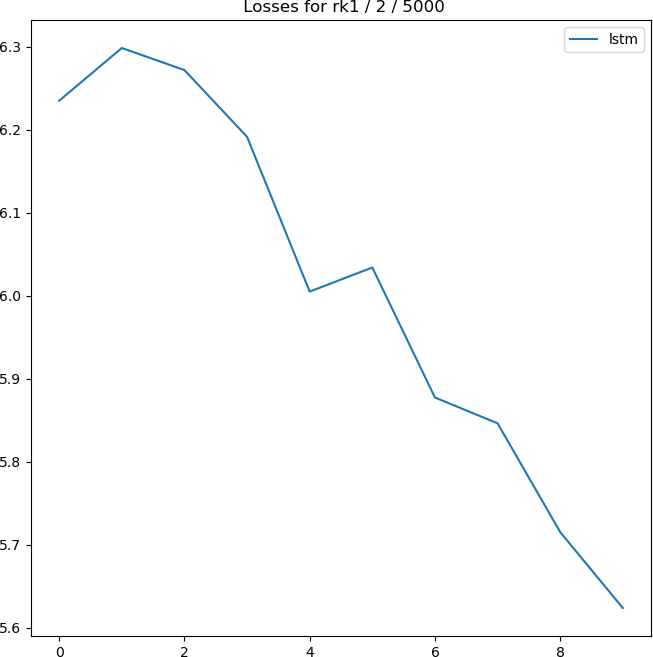
And in the project’s ../runs/rk1_sv directory, I have the following two files:
- losses_1_5000.pt
- lstm_1.pt
I haven’t tried loading them just yet. Will eventually give that a try. (But, for now, calling it a day. Well, after I commit all the changes to the modules and draft blog post(s).)
Check Saved Checkpoint/Log
Thought it best I add a little code to make sure those saved files contain what I expect them to contain. Without going into too much detail. I did refactor the ld_chkpt function in the utils module to allow for returning the checkpoint loaded from the specified file. (Won’t bother showing that.)
Now here’s a very simple bit of test code. And the resulting output.
... ...
if tst_chkpt:
fini_ep = 1
d_tst = 5000
cp_pth = cfg.sv_dir/f"lstm_{fini_ep}.pt"
lg_pth = cfg.sv_dir/f"losses_{fini_ep}_{d_tst}.pt"
optr = optim.Adam(lstm.parameters(), lr=lr)
chkpt = utl.ld_chkpt(cp_pth, lstm, optr, rtn_chk=True)
print(f"\nchkpt keys: {chkpt.keys()}")
print(f"\nmodel_state_dict keys: {len(chkpt["model_state_dict"].keys())} -> {chkpt["model_state_dict"].keys()}")
print(f'\nembed weight: {chkpt["model_state_dict"]["embed.weight"].shape}\n{chkpt["model_state_dict"]["embed.weight"]}')
loss_nms = ["lstm"]
lgr_loss = Logger(cfg.run_nm, cfg.sv_chk_cyc, loss_nms)
lgr_loss.from_file(cfg.sv_dir, fini_ep, iter=d_tst)
print(f"\nlogger losses: {lgr_loss.losses}")
(mclp-3.12) PS F:\learn\mcl_pytorch\proj8> python nlp.py -rn rk1 -bs 32
{'run_nm': 'rk1', 'batch_sz': 32, 'dataset_nm': 'no_nm', 'sv_img_cyc': 150, 'sv_chk_cyc': 50, 'resume': False, 'start_ep': 0, 'epochs': 5, 'num_res_blks': 9, 'x_disc': 1, 'x_genr': 1, 'x_eps': 0, 'use_lrs': False, 'lrs_unit': 'batch', 'lrs_eps': 5, 'lrs_init': 0.01, 'lrs_steps': 25, 'lrs_wmup': 0}
image and checkpoint directories created: runs\rk1_img & runs\rk1_sv
took 3.402942900080234 to generate pairs
loading runs\rk1_sv\lstm_1.pt
chkpt keys: dict_keys(['batch_sz', 'epoch', 'run_nm', 'model_state_dict', 'optimizer_state_dict', 'lr_schd'])
model_state_dict keys: 15 -> odict_keys(['embed.weight', 'lstm.weight_ih_l0', 'lstm.weight_hh_l0', 'lstm.bias_ih_l0', 'lstm.bias_hh_l0', 'lstm.weight_ih_l1', 'lstm.weight_hh_l1', 'lstm.bias_ih_l1', 'lstm.bias_hh_l1', 'lstm.weight_ih_l2', 'lstm.weight_hh_l2', 'lstm.bias_ih_l2', 'lstm.bias_hh_l2', 'fc.weight', 'fc.bias'])
embed weight: embed weight: torch.Size([14224, 128])
tensor([[ 2.1097, 1.6909, 1.0060, ..., 0.2525, 0.9043, 0.4359],
[ 2.2242, 1.2280, -1.3579, ..., 0.4016, 0.7428, 0.3072],
[-0.8883, 0.5279, -1.7787, ..., 1.0637, -0.7584, -0.3141],
...,
[ 0.4539, 0.3829, -0.3127, ..., 2.4416, 1.4977, 1.4447],
[ 0.0198, 0.1520, 0.3908, ..., -1.6778, -0.6252, 0.9618],
[ 1.6620, -0.6423, 1.6617, ..., 0.5960, 1.1427, 0.2758]],
device='cuda:1')
logger losses: {'lstm': [6.235020160675049, 6.2984843254089355, 6.27188777923584, 6.191473007202148, 6.005039215087891, 6.034036159515381, 5.877450942993164, 5.846343517303467, 5.71530818939209, 5.623859405517578]}
And that all looks to be about right. Can’t really say anything about those embed weights—right or wrong. But you may recall that the embedding layer was defined as self.embed = nn.Embedding(vcb_sz, mbd_dim) which in our case gave us (embed): Embedding(14224, 128).
Longer Training Run
I am going to run 5 epoch training run. And see if things continue to work as expected. But I am going to modify the loop to use tqdm so that I have visual confirmation things are running as expected. Won’t show the refacorted code, but did have to make some adjustments from my earlier code using enumerate. tqdm doesn’t provide a iteration index; so added a counter.
(mclp-3.12) PS F:\learn\mcl_pytorch\proj8> python nlp.py -rn rk1 -bs 32 -ep 5
{'run_nm': 'rk1', 'batch_sz': 32, 'dataset_nm': 'no_nm', 'sv_img_cyc': 150, 'sv_chk_cyc': 50, 'resume': False, 'start_ep': 0, 'epochs': 5, 'num_res_blks': 9, 'x_disc': 1, 'x_genr': 1, 'x_eps': 0, 'use_lrs': False, 'lrs_unit': 'batch', 'lrs_eps': 5, 'lrs_init': 0.01, 'lrs_steps': 25, 'lrs_wmup': 0}
image and checkpoint directories created: runs\rk1_img & runs\rk1_sv
took 3.3732511000707746 to generate pairs
running epochs in range(0, 5)
epoch 1: 100%|███████████████████████████████████████████████████████████████████| 13418/13418 [08:26<00:00, 26.47it/s]
epoch 1: 100%|███████████████████████████████████████████████████████████████████| 13418/13418 [08:25<00:00, 26.55it/s]
epoch 1: 100%|███████████████████████████████████████████████████████████████████| 13418/13418 [08:26<00:00, 26.50it/s]
epoch 1: 100%|███████████████████████████████████████████████████████████████████| 13418/13418 [08:25<00:00, 26.55it/s]
epoch 1: 100%|███████████████████████████████████████████████████████████████████| 13418/13418 [08:25<00:00, 26.53it/s]
And here’s the plot of the losses generated in the 5 epochs of training.
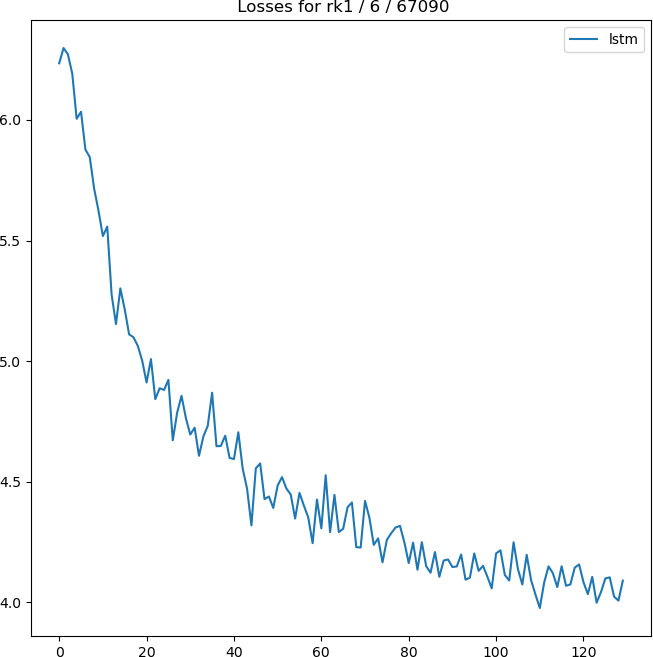
Check Saved Checkpoint/Log Again
I refactored the code shown above to work with the current file name structure for the saved checkpoint and log files. And, plotted the losses rather than printing out the list. Wasn’t going to include the refactored code, but why not.
if tst_chkpt:
iters = len(tk_ldr) * cfg.start_ep
cp_pth = cfg.sv_dir/f"lstm_{cfg.start_ep}.pt"
lg_pth = cfg.sv_dir/f"losses_{cfg.start_ep}_{iters}.pt"
optr = optim.Adam(lstm.parameters(), lr=lr)
chkpt = utl.ld_chkpt(cp_pth, lstm, optr, rtn_chk=True)
print(f"\nchkpt keys: {chkpt.keys()}")
print(f"\nmodel_state_dict keys: {len(chkpt["model_state_dict"].keys())} -> {chkpt["model_state_dict"].keys()}")
print(f'\nembed weight: {chkpt["model_state_dict"]["embed.weight"].shape}\n{chkpt["model_state_dict"]["embed.weight"]}')
loss_nms = ["lstm"]
lgr_loss = Logger(cfg.run_nm, cfg.sv_chk_cyc, loss_nms)
lgr_loss.from_file(cfg.sv_dir, cfg.start_ep-1, iter=iters)
lgr_loss.plot_losses()
And, here’s the terminal output. You will just have believe me that the losses plot matches the one above.
(mclp-3.12) PS F:\learn\mcl_pytorch\proj8> python nlp.py -rn rk1 -bs 32 -se 5
{'run_nm': 'rk1', 'batch_sz': 32, 'dataset_nm': 'no_nm', 'sv_img_cyc': 150, 'sv_chk_cyc': 50, 'resume': False, 'start_ep': 5, 'epochs': 5, 'num_res_blks': 9, 'x_disc': 1, 'x_genr': 1, 'x_eps': 0, 'use_lrs': False, 'lrs_unit': 'batch', 'lrs_eps': 5, 'lrs_init': 0.01, 'lrs_steps': 25, 'lrs_wmup': 0}
image and checkpoint directories created: runs\rk1_img & runs\rk1_sv
took 3.828144000002794 to generate pairs
loading runs\rk1_sv\lstm_5.pt
chkpt keys: dict_keys(['batch_sz', 'epoch', 'run_nm', 'model_state_dict', 'optimizer_state_dict', 'lr_schd'])
model_state_dict keys: 15 -> odict_keys(['embed.weight', 'lstm.weight_ih_l0', 'lstm.weight_hh_l0', 'lstm.bias_ih_l0', 'lstm.bias_hh_l0', 'lstm.weight_ih_l1', 'lstm.weight_hh_l1', 'lstm.bias_ih_l1', 'lstm.bias_hh_l1', 'lstm.weight_ih_l2', 'lstm.weight_hh_l2', 'lstm.bias_ih_l2', 'lstm.bias_hh_l2', 'fc.weight', 'fc.bias'])
embed weight: torch.Size([14224, 128])
tensor([[ 2.0624, 1.5394, 1.1943, ..., 0.2985, 1.1139, 0.4762],
[ 2.7643, 1.6831, -1.3117, ..., 0.4939, 0.7966, 0.6349],
[-1.3533, 0.5633, -2.2340, ..., 1.4532, -0.6051, -0.3367],
...,
[ 0.4408, 0.5987, -0.2252, ..., 2.2253, 1.5692, 1.5502],
[ 0.3452, 0.4400, 0.7182, ..., -1.8772, -0.6345, 1.1479],
[ 1.8017, -0.7051, 1.8758, ..., 0.3820, 1.4425, 0.2332]],
device='cuda:1')
And, perhaps more importantly, the embed weights are different from the ones obtained during the test run.
Done
I think that’s it for this one. Will backup checkpoint/log files. Then see if I can get training restarted in a proper fashion. And, go from there.
I also want the error logging to start with the last saved version each time I resume training. So, I believe, a little refactoring required for that.
I may look at coding a simple test to have a look at the model’s current performance. Curiosity!
Until next time may your model’s training progress smoothly and efficiently.